英伟达的GPU短缺未来还会持续吗,瓶颈是什么?解析与展望

本文由半导体产业纵横(ID:ICVIEWS)编译自eetimes
尽管GPU需求本身很大,但供给根本跟不上。

自2022年11月Open AI发布ChatGPT以来,生成式AI(人工智能)需求在全球爆发式增长。这一系列AI应用运行在配备有NVIDIA GPU等AI半导体的AI服务器上。
不过,根据中国台湾研究公司TrendForce在 2023年12月14日的预测,AI服务器出货量增幅不会如预期。预计2022年AI服务器仅占所有服务器出货量的6%,2023年为9%,2024年为13%,2025年为14%,2026年为16%。(图1)。
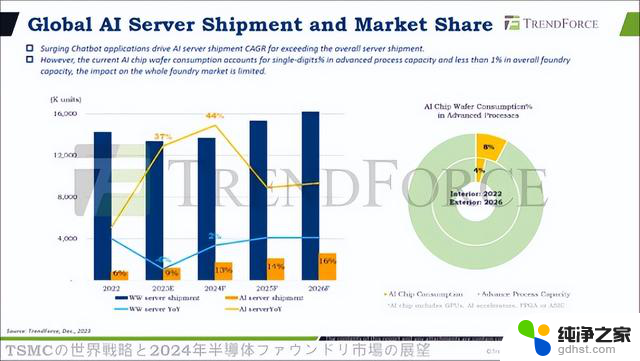
图1.服务器出货数量、AI服务器占比、AI芯片晶圆占比。来源:TrendForce
其原因被认为是人工智能半导体的限速供应。目前,NVIDIA的GPU垄断了约80%的AI半导体,制造在台积电进行。在后续的流程中,会利用CoWoS进行封装,但是CoWoS的产量目前是一个瓶颈。
另外,在CoWoS中,GPU周围放置了多个HBM(高带宽内存),这些HBM是堆叠的DRAM,这个HBM也被认为是瓶颈之一。
那么,为什么台积电的CoWoS(Chip on Wafer on Substrate)产能持续不足呢?另外,虽然有三星电子、SK海力士、美光科技三大DRAM厂商,但为什么HBM也不够呢?
本文讨论了这些细节。NVIDIA GPU 等 AI 半导体的短缺预计将持续数年或更长时间。
图 2显示了 NVIDIA 的 GPU 是如何在台积电制造的。首先,在预处理中,分别创建GPU、CPU、内存(DRAM)等。这里,由于台积电不生产DRAM,因此似乎是从SK海力士等DRAM制造商那里获得HBM。
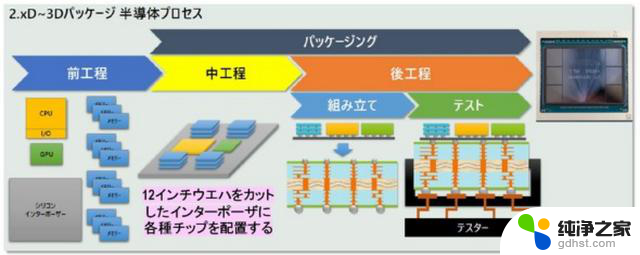
图2.2.5D 到 3D 中出现的制造工艺。来源:Tadashi Kamewada
接下来,将GPU、CPU、HBM等粘合到“硅中介层”上(Chip on Wafer,或CoW)。硅中介层具有预先形成的布线层和硅通孔(TSV)以连接芯片。
这一步骤完成后,将中介层贴到基板上(Wafer on Substrate,简称WoS),进行各种测试,CoWoS封装就完成了。
图3显示了CoWoS的横截面结构。两个逻辑芯片(例如 GPU 和 CPU)以及具有堆叠式 DRAM 的 HBM 被粘合到硅中介层上,硅中介层上形成有布线层和 TSV。中介层通过与铜凸块连接到封装基板,并且该基板通过封装球连接到电路板。
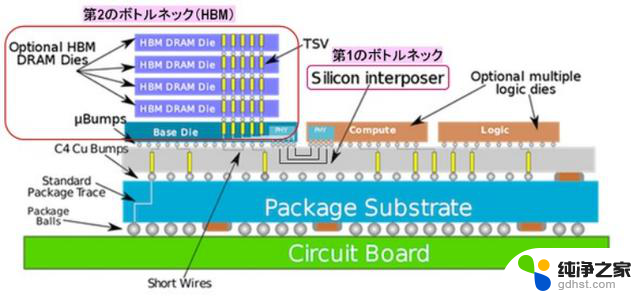
图3.CoWoS结构和NVIDIA GPU等AI半导体的两个瓶颈。来源:WikiChip
在这里,我们认为第一个瓶颈是硅中介层,第二个瓶颈是HBM,这是导致NVIDIA GPU短缺的原因。
图 4 显示了自 2011 年以来 CoWoS 的换代情况。首先,我们可以看到,每一代的硅中介层都变得巨大。此外,安装的 HBM 数量也在不断增加。
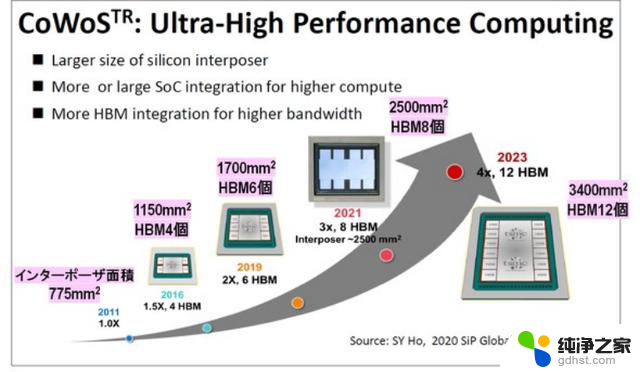
图4.每代HBM的转接层面积和安装数量增加。来源:台积电
图 5 显示了从 CoWoS Gen 1 到 Gen 6 的 12 英寸晶圆中安装的 Logic 芯片类型、HBM 标准和安装数量、硅中介层面积以及可获得的中介层数量。

图5. CoWoS 代次、HBM 安装数量、12 英寸晶圆转接层数量。
可以看出,自第三代以来,HBM的安装数量持续增长了1.5倍。此外,HBM 的标准也发生了变化,性能也得到了提高。此外,随着中介层面积的增加,可以从 12 英寸晶圆获得的中介层数量减少。
然而,这个采集数只是“将12英寸晶圆的面积除以中介层的面积得到的值”,实际的采集次数要小得多。
2023 年发布的第 6 代 CoWoS 转接板的面积为 3400 mm2,但如果我们假设它是一个正方形,它将是 58 mm × 58 mm。如果将其放置在 12 英寸晶圆上,晶圆边缘上的所有转接层都将有缺陷。然后,一个58 mm × 58 mm中介层最多只能从 12 英寸晶圆上获取 9 个芯片。
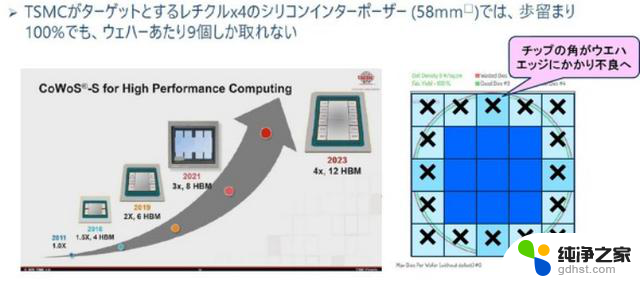
图6. 12英寸晶圆能获得多少个转接层。来源:Tadashi Kamewada
此外,在中介层上形成布线层和TSV,但良率约为60~70%,因此从12英寸晶圆上可以获得的良好中介层数量最多为6个。
使用这款转接板制作的 CoWoS 的代表性 GPU 是 NVIDIA 的“H100”,它在市场上竞争激烈,交易价格高达 40,000 美元。
那么,台积电的CoWoS制造产能有多大呢?
在 2023 年 11 月 14 日举行的 DIGITIMES 研讨会“生成式 AI 浪潮中 2024 年全球服务器市场的机遇与挑战”中显示,2023 年第二季度的产能为每月 13K~15K 件。据预测,2024 年第二季度月产量将翻倍至 30K~34K,从而缩小 NVIDIA GPU 的供需缺口。
然而,这种前景还很遥远。这是因为,截至 2024 年 4 月,NVIDIA 仍然没有足够的 GPU。而TrendForce集邦咨询在4月16日的新闻中表示,到2024年底,台积电的CoWoS产能将达到每月40K左右,到2025年底将翻倍。
此外,TrendForce集邦咨询报道称,NVIDIA将发布B100和B200,但这些转接板可能比 58 mm × 58 mm还要大。这意味着从12英寸晶圆上可以获得的优质中介层的数量将进一步减少,因此即使台积电拼命尝试增加CoWoS产能,也无法生产足够的GPU来满足需求。
这款GPU CoWoS中介层的巨大和台积电产能的增加,无论走多远都没有止境。
有人建议使用515×510mm棱柱形有机基板代替12英寸晶圆作为中介层。此外,美国的英特尔公司还提议使用矩形玻璃基板。当然,如果可以使用大型矩形基板,则可以比圆形12英寸晶圆更有效地获得大量中介层。
然而,为了在矩形基板上形成布线层和TSV,需要专用的制造设备和传输系统。考虑到这些的准备工作,这需要时间和金钱。接下来解释一下HBM的情况,这是另一个瓶颈。
如图 4 和图 5 所示,HBM 的数量随着 CoWoS 的产生而增加,这也导致了中介层的巨大。DRAM制造商不应继续制造相同标准的HBM。随着 CoWoS 的发展,HBM 的各种性能需要改进。HBM 的路线图如图 7 所示。
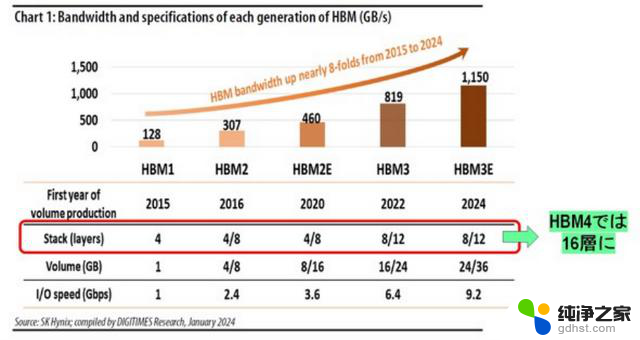
图 7.HBM 路线图和 HBM 堆叠的 DRAM 数量。来源:DIGITIMES Research
首先,HBM 必须提高每秒交换数据的带宽,以配合 GPU 性能的提高。具体来说,2016 年 HBM1 的带宽为 128 GB/s,而 HBM3E 的带宽将扩大约 10 倍,达到 1150 GB/s,将于 2024 年发布。
接下来,HBM 的内存容量 (GB) 必须增加。为此,有必要将堆叠在 HBM 中的 DRAM 芯片数量从 4 个增加到 12 个。下一代 HBM4 的 DRAM 层数预计将达到 16 层。
此外,HBM 的 I/O 速度 (GB/s) 也必须提高。为了同时实现所有这些目标,我们必须不惜一切代价实现DRAM的小型化。图8显示了按技术节点划分的DRAM销售比例的变化。2024 年将是从 1z (15.6 nm) 切换到 1α (13.8 nm) 的一年。之后,小型化将以 1 nm 的增量进行,例如 1β (12.3 nm)、1γ (11.2 nm) 和 1δ (10 nm)。
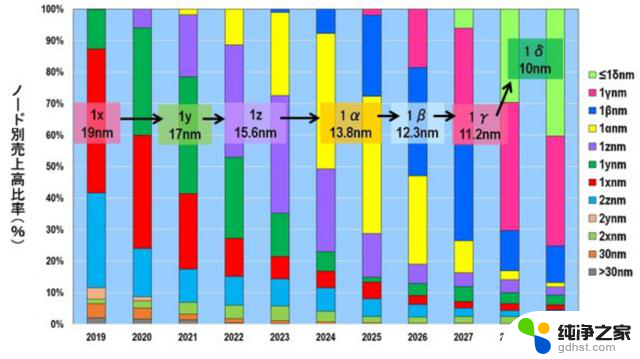
图8.按技术节点划分的DRAM销售额百分比 。来源:Yole Intelligence
请注意,括号中的数字是该代DRAM芯片中实际存在的最小加工尺寸。
DRAM制造商必须以1nm的增量进行小型化,以实现高集成度和速度。因此,EUV(极紫外)光刻技术已开始应用于精细图案的形成(图9)。
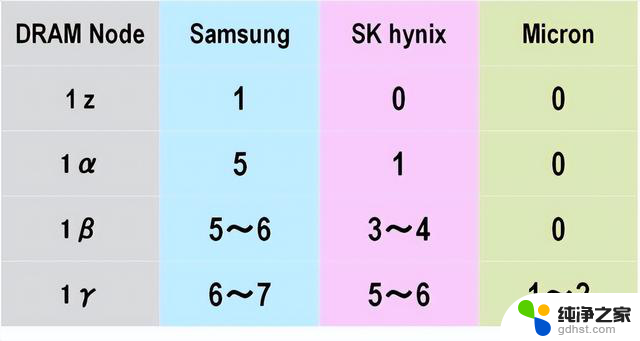
图9.DRAM厂商应用的EUV层数。来源:Yole Intelligence
最早在 DRAM 中使用 EUV 的公司是三星,在 1z 代中仅应用了一层。不过,这只是借用了三星逻辑代工厂的一条每月最大产量为 10,000 片晶圆的巨大 DRAM 生产线来实践 EUV 应用。因此,从真正意义上讲,三星只是从 1α 年开始在 DRAM 中使用 EUV,当时它在五层 DRAM 中使用了 EUV。
其次是在 HBM 领域市场份额第一的 SK hynix,它在 1α 生产时应用了 EUV。该公司计划在 2024 年转向 1β,并有可能在三到四层应用 EUV。因此,迄今只有几个 EUV 单元的 SK hynix 将在 2024 年之前推出 10 个 EUV 单元。同样拥有逻辑代工厂的三星公司被认为将拥有超过 30 个 EUV 单元。
最后,美光公司一直奉行尽可能少使用 EUV 的战略,以便比其他任何地方都更快地推进其技术节点。事实上,美光在 1 β 之前都不使用 EUV。在开发过程中,它还计划在 1 γ 时不使用 EUV,而是使用 ArF 沉浸 + 多图案技术,但由于它发现很难提高产量,因为没有更多的匹配空间,因此预计将从 1 γ 开始引入 EUV。
这三家 DRAM 制造商目前正在尝试使用镜头孔径为 NA = 0.33 的 EUV,但据认为,它们正在考虑从 2027-2028 年起改用高 NA。因此,DRAM 制造商的微型化进程仍将越走越远。
现在,有多少 HBM 将采用这些最先进的工艺生产?
图 10 显示了 DRAM 出货量、HBM 出货量以及 HBM 占 DRAM 出货量的百分比。如本节开头所述,ChatGPT 于 2022 年 11 月发布,从而使英伟达公司的 GPU 在 2023 年取得重大突破。
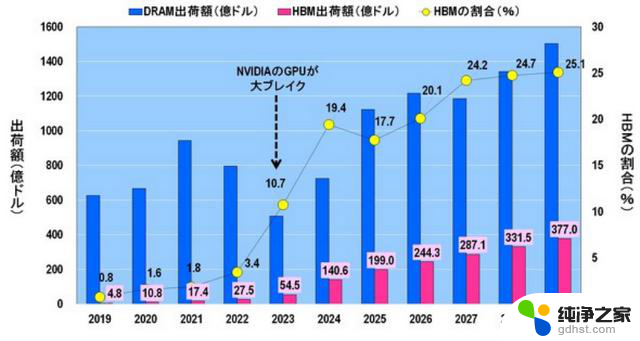
图10.DRAM 出货量、HBM 出货量和 HBM 所占百分比。来源:Yole Intelligence
与此同时,HBM 的出货量也迅速增长:HBM 的出货量从 2022 年的 27.5 亿美元(3.4%)增长到 2023 年的 54.5 亿美元(10.7%),几乎翻了一番,到 2024 年更是翻了一番,达到 140.6 亿美元(19.4%)。
从 DRAM 的出货量来看,2021 年由于对 Corona 的特殊需求而达到高峰,但 2023 年这种特殊需求结束后,出货量急剧下降。此后,出货量有望恢复,并在 2025 年超过 2021 年的峰值。此外,从 2026 年起,出货量预计将继续增长,尽管会有一些起伏,到 2029 年将超过 1500 亿美元。
另一方面,HBM 的出货量预计将在 2025 年后继续增长,但 HBM 在 DRAM 出货量中所占的份额将在 2027 年后达到 24-25% 的饱和状态。这是为什么呢?
如图 11 所示,通过观察各种 HBM 的出货量和 HBM 的总出货量,可以揭开谜底。
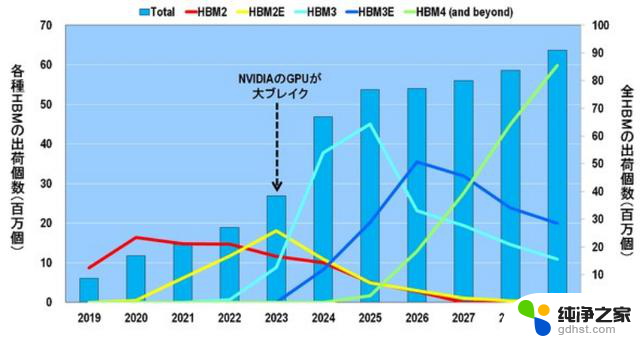
图11.各种 HBM 和所有 HBM 的出货量。来源:Yole Intelligence
首先,在 2022 年之前,HBM2 是主要的出货量。其次,2023 年,英伟达的 GPU 取得重大突破,HBM2E 取代 HBM2 成为主流。此外,HBM3 将在今年 2024 至 2025 年间成为主流。2026-2027 年,HBM3E 将成为出货量最大的产品,而从 2028 年开始,HBM4 将扮演主角。
换句话说,HBM 将以大约两年的间隔经历世代更迭。这意味着 DRAM 制造商必须继续以 1 纳米为单位进行微型化,同时每两年更新一次 HBM 标准。
因此,如图 11 所示,2025 年后所有 HBM 的出货量几乎不会增加。这并不是因为 DRAM 制造商懈怠,而是因为他们必须尽最大努力生产最先进的 DRAM 和最先进的 HBM。
此外,2025 年后 HBM 出货量不会大幅增长的原因之一是堆叠在 HBM 中的 DRAM 芯片数量将增加(图 12):随着 GPU 性能的提高,HBM 的内存容量(GB)也必须增加,因此堆叠在 HBM 2 和 HBM2E 中的 DRAM 数量将增加。HBM2 和 HBM2E 中堆叠的 DRAM 数量将增加到 4-8 个 DRAM,HBM3 和 HBM3E 中堆叠的 DRAM 数量将增加到 8-12 个,HBM4 中堆叠的 DRAM 数量将增加到 16 个。
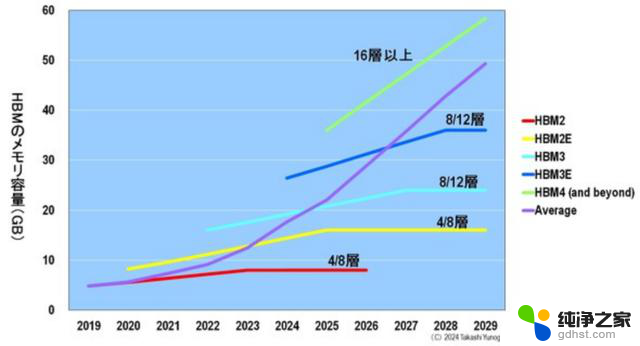
图12.每个 HBM 的内存容量(GB)和 HBM 中的 DRAM 芯片堆叠数。来源:Yole Intelligence
这意味着 HBM2 只需要 4 到 8 个 DRAM,而 HBM4 将需要 2 到 4 倍的 DRAM,即 16 个 DRAM。这意味着,在 HBM4 时代,DRAM 制造商可以生产比 HBM2 多 2-4 倍的 DRAM,但出货量仍与 HBM 相同。
因此,随着 DRAM 继续以 1nm 的增量缩小,HBM 两年换一代,HBM 中堆叠的 DRAM 数量每一代都在增加,预计从 2025 年起,HBM 的总出货量将达到饱和。
那么,HBM 的短缺会持续下去吗? DRAM 制造商是否无法进一步增加 HBM 的出货量?
我们已经解释了 DRAM 制造商无法大幅增加 HBM 出货量的原因,但 DRAM 制造商仍然能够达到他们的极限,倘若超过这个极限,他们就会尝试大量生产 HBM。这是因为 HBM 的价格非常高。
图 13 显示了各种 HBM 和普通 DRAM 的每 GB 平均价格。普通 DRAM 和 HBM 在发布时的每 GB 价格都是最高的。虽然趋势相同,但普通 DRAM 和 HBM 的每 GB 价格相差 20 倍以上。为了比较普通 DRAM 和 HBM 的每 GB 平均价格,图 13 中的图表显示了普通 DRAM 的 10 倍价格。
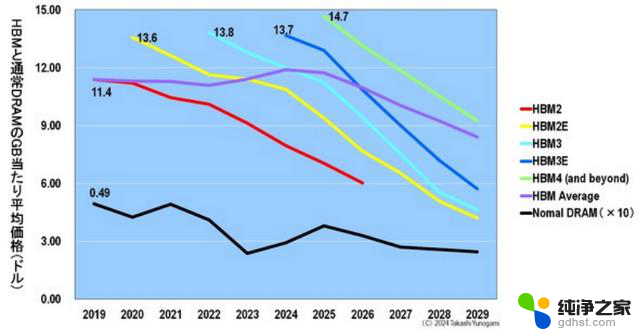
图13.各种 HBM 和普通 DRAM 的每 GB 平均价格比较。来源:Yole Intelligence
与普通 DRAM 的 0.49 美元相比,比较每 GB 的价格,在刚刚发布后的最高价格时,HBM2 的每 GB 价格大约是普通 DRAM 的 23 倍(11.4 美元),HBM2E 的每 GB 价格大约是普通 DRAM 的 28 倍(13.6 美元),HBM4 的每 GB 价格大约是普通 DRAM 的 30 倍(14.7 美元)。
此外,图 14 显示了各种 HBM 的平均价格。价格最高的 HBM2 为 73 美元,HBM2E 为 157 美元,HBM3 为 233 美元,HBM3E 为 372 美元,HBM4 则高达 560 美元。
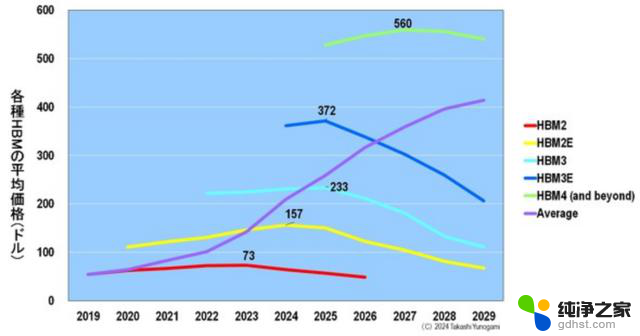
图14.各种 HBM 和标准 DRAM 的每 GB 平均价格比较。来源:Yole Intelligence
图 15显示了 HBM 的价格有多昂贵。例如,DRAM厂商在1z工艺中生产的16GB DDR5 DRAM最多为3~4美元。不过,今年,SK海力士发布的HBM3E售价将比361美元高出90~120倍。
DDR(双倍数据速率)是一种内存标准。数据传输速度越来越快,DDR5 的速度是 DDR4 的两倍,DDR6 的速度是 DDR5 的两倍。2024 年将是 DDR4 向 DDR5 转变的一年,DRAM 制造商也必须不断更新其 DDR 标准。
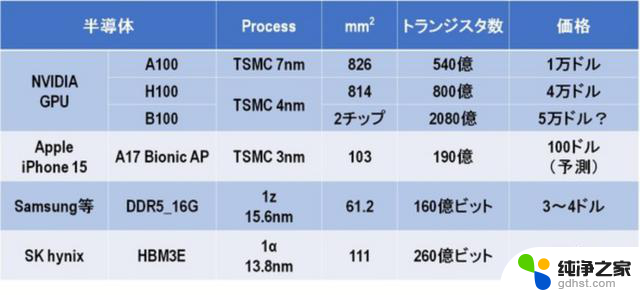
图15.各种半导体工艺、芯片尺寸、晶体管数量(位数)和平均价格的比较 。
回到 HBM,HBM3E 的芯片尺寸与最新 iPhone 17 的 A15 仿生 AP(应用处理器)大致相同,后者采用台积电最先进的 3nm 工艺生产,但价格高出 3.6 倍。DRAM的HBM高于高级逻辑。这是令人震惊的。而由于价格如此之高,DRAM厂商将竭尽全力增加出货量,以主导HBM的霸主地位。
让我们来看看三家DRAM制造商的路线图。
图 16显示了 2015~2024 年三家 DRAM 制造商如何生产 HBM。
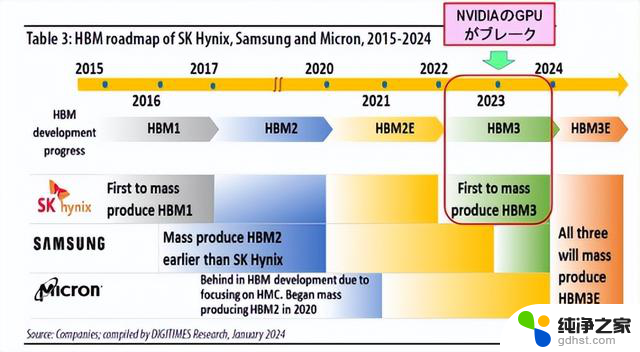
图16. SK 海力士、三星和美光的 HBM 路线图。来源:DIGITIMES Research
HBM1 首次成功量产的是 SK 海力士。然而,就HBM2而言,三星比SK海力士率先实现量产。当 NVIDIA 的 GPU 在 2023 年取得重大突破时,SK海力士率先成功量产HBM3。这为SK海力士带来了巨大的利益。
另一方面,另一家 DRAM 制造商美光最初开发了与 HBM 标准不同的混合内存立方体 (HMC)。然而,联合电子器件工程委员会 (JEDEC) 是一个促进美国半导体标准化的行业组织,已正式认证了 HBM 标准而不是 HMC。因此,美光从2018年开始放弃HMC的开发,进入HBM的开发,远远落后于两家韩国制造商。
因此,在HBM 的市场份额中, SK 海力士为 54%,三星为 41%,美光为 5%。
拥有最大HBM份额的SK海力士将于2023年开始在其NAND工厂M15生产HBM。此外,HBM3E 将于 2024 年上半年发布。此外,在 2025 年,目前正在建设中的 M15X 工厂将专门为 HBM 重新设计,以生产 HBM3E 和 HBM4。
另一方面,想要赶上SK海力士的三星计划于2023年在三星显示器的工厂开始生产HBM,2024年将HBM的产能翻倍,并在SK海力士之前于2025年量产HBM4。
一直落后的美光的目标是在2024~2025年跳过HBM3,与HBM3E竞争,并在2025年获得20%的市场份额。此外,到2027~2028年,该公司还设定了在HBM4和HBM4E量产方面赶上韩国两大制造商的目标。
这样一来,三家DRAM厂商之间的激烈竞争可能会突破HBM出货量的饱和,从而消除HBM的短缺。
在本文中,我们解释了 NVIDIA GPU 等 AI 半导体全球短缺的原因。
1、NVIDIA 的 GPU 采用台积电的 CoWoS 封装制造。这个CoWoS的容量是完全不够的。其原因是配备 GPU、CPU 和 HBM 等芯片的硅中介层每一代都变得越来越大。台积电正试图增加这个中间工艺的容量,但随着GPU一代的推进,中介层也会变得巨大。
2、CoWoS 的 HBM 短缺。造成这种情况的原因是DRAM制造商必须继续以1nm的增量进行小型化,HBM标准被迫每两年更换一次,并且HBM中堆叠的DRAM芯片数量随着每一代的增加而增加。DRAM制造商正在尽最大努力生产HBM,但预计出货量将在2025年之后饱和。然而,由于HBM的价格非常高,DRAM厂商之间竞争激烈,这可能导致HBM的短缺。
如上所述,有两个瓶颈导致 NVIDIA 的 GPU 短缺:台积电的制造产能短缺和 HBM 短缺,但这些问题不太可能在大约一年内得到解决。因此,预计未来几年 NVIDIA 的 GPU 短缺将会继续下去。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。